
While large-scale pre-trained text-to-image models can synthesize diverse and high-quality human-centric images, an intractable problem is how to preserve the face identity for conditioned face images. Existing methods either require time-consuming optimization for each face-identity or learning an efficient encoder at the cost of harming the editability of models. In this work, we present an optimization-free method for each face identity, meanwhile keeping the editability for text-to-image models. Specifically, we propose a novel face-identity encoder to learn an accurate representation of human faces, which applies multi-scale face features followed by a multi-embedding projector to directly generate the pseudo words in the text embedding space. Besides, we propose self-augmented editability learning to enhance the editability of models, which is achieved by constructing paired generated face and edited face images using celebrity names, aiming at transferring mature ability of off-the-shelf text-to-image models in celebrity faces to unseen faces. Extensive experiments show that our methods can generate identity-preserved images under different scenes at a much faster speed.
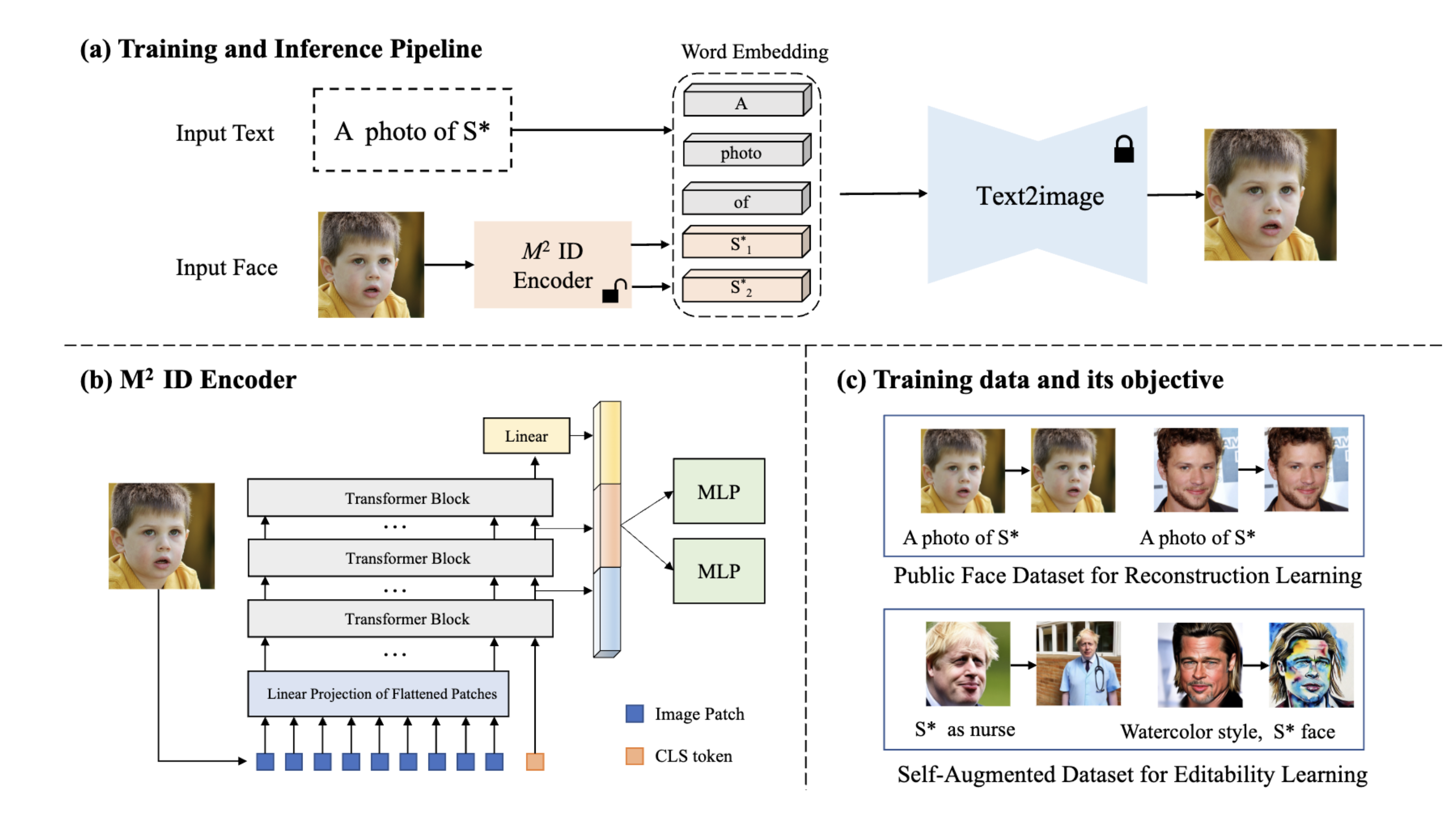
Overview of the proposed DreamIdentity: (a) The training and inference pipeline. The input face image is first encoded into multi-word embeddings (denoted by S*) by our proposed M2 ID encoder. Then S* are associated with the text input to generate face-identity preserved image in the text-aligned scene. (b) The architecture of M2 ID encoder, where a ViT-based face identity encoder is adopted as the backbone and the extracted multi-scale features are projected to multi-word embedding. (c) The composition of the training data and its objectives. The training data consists of a public face dataset for reconstruction and a self-augmented dataset for editability learning.
Given a face identify and its gaze location on the canvas, our method can generate a series of images that maintain the same identity while following the editing prompts in the same location.

Our method can preserve core ID information while performing Text-guided Portrait Style Tranfer. (We use ControlNet-Canny to preserve structure features)

Our method can work well on the fientuned checkpoint, such as Envvi/Inkpunk-Diffusion
